Премия Тьюринга, «нобелевка» по информатике, в этом году вручена за обучение ИИ

Ассоциация вычислительной техники наградила Эндрю Г. Барто и Ричарда С. Саттона за фундаментальные разработки в области обучения с подкреплением. Их исследования заложили основу одного из ключевых направлений искусственного интеллекта.
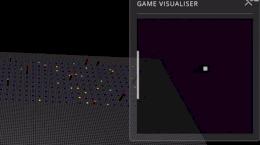
Этот метод позволяет интеллектуальным системам обучаться на основе вознаграждений, подобно тому, как дрессируют животных. Барто и Саттон первыми сформулировали его как математическую модель, основанную на процессах принятия решений Маркова, где агент учится в неопределенной среде, пытаясь получить максимальное долгосрочное вознаграждение.
Ученые разработали алгоритм временных различий, методы градиента политики и нейросетевые подходы для улучшения прогнозов. Их книга «Обучение с подкреплением: Введение» (Reinforcement Learning: An Introduction, 1998) стала ключевым руководством, процитированным более 75 000 раз.
Обучение с подкреплением стало основой множества прорывов в ИИ. В 2016 году программа AlphaGo победила лучших игроков в го, а технология RLHF используется в развитии чат-ботов, таких как ChatGPT. Метод также применяется в робототехнике, рекламе, оптимизации сетей и даже в проектировании микросхем.
Исследования Барто и Саттона оказали влияние не только на ИИ, но и на когнитивную науку и нейробиологию, внеся вклад в понимание принципов работы дофаминовой системы мозга. Как отметили в АВТ, их открытия продолжают развивать ИИ и вдохновляют новые поколения ученых.
Премия Тьюринга, финансируемая Google, — одна из самых престижных в области вычислительных наук, по значимости в своей области ее сравнивают с Нобелевской.
Премию Тьюринга, нобелевку для информатиков, получил исследователь случайности в вычислениях